Criterios de propagación
Introduction
In order to calculate each analysis dimension and obtain the level of service, Obsidian allows the definition of criticality and the configuration of different propagation criteria, aiming to adapt the calculation of each dimension to the characteristics of the service.
Below is an explanation of what these propagation criteria are and how the level of service is calculated in each case.
Criticality
Criticality is the degree of importance that a probe or an element has within the service. This parameter defines the extent to which the value of the probe will be propagated. So, a value of 0 will not propagate any value to the service, while a value of 1 will fully propagate the value.
The calculation of the value is carried out as follows:

EXAMPLE 1:
Let's say that the "Current load" capacity probe returns a value of 0. Since the criticality is 1, it will propagate the value of the probe in full:
Propagated value = 0 + (100 - 0) * (1 - 1) = 0 + 100 * 0 = 0

However, if its criticality is reduced to 0.25, the propagated value changes, affecting the service to a lesser extent:
Propagated value = 0 + (100 - 0) * (1 - 0.25) = 0 + 100 * 0.75 = 0 + 75 = 75

This way, when reducing the criticality to 0, the impact on the service is completely canceled. Regardless of the value returned by the probe, an OK (green) with a value of 100 will be propagated:
Propagated value = 0 + (100 - 0) * (1 - 0) = 0 + 100 = 100

EXAMPLE 2:
In this case, the availability probe "Check" (orange) returns a value of 85 with the criticality at 1:

However, when reducing its criticality to 0.05, the propagated value would be, according to the formula:
85 + (15 * 0.95) = 99.25 → 99

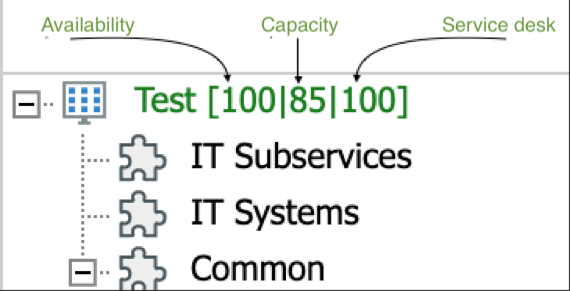
It should be noted that the probe in the first example is a capacity probe, while the second example corresponds to an availability probe. Each of these values are calculated separately to measure the state of the service. In Obsidian, it is possible to see the value of each dimension of the tree nodes, which are shown in [- | - | -] format. The first value corresponds to availability, the second to capacity and the third to service desk.
Propagation rules
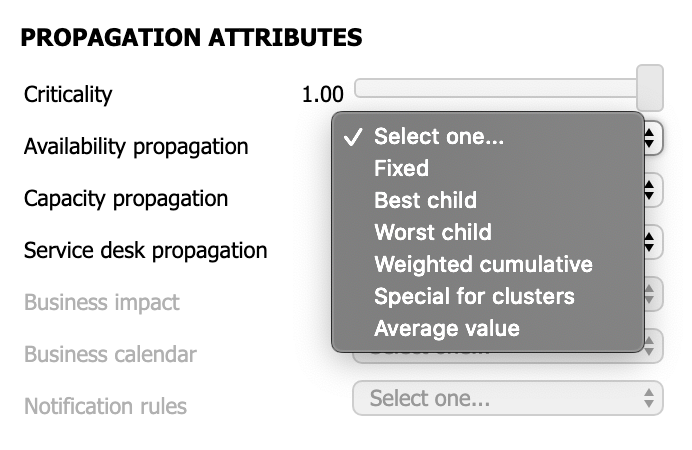
While criticality weighs the impact of a given node on its parents, propagation rules weigh the value of a node's child nodes to define their impact on such node. Each parent node may have a different rule for propagating the values of each dimension (availability, capacity, and service desk).
Fixed

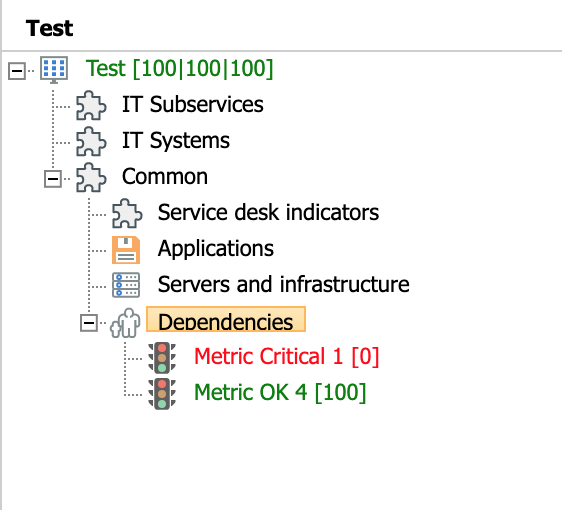
This rule propagates a fixed value (100), regardless of its child components. It is usually used for maintenance or specific interventions.
In the following example, there is a critical probe that returns a value of 0. However, when using the propagation rule "Fixed" on the "Dependencies" node, the service is not affected, and it displays an availability value of 100:
Best child

This rule propagates the value of the child node with the highest value. This option is useful for cases of an active-passive cluster, for example.
Below are two probes: one with a Warning (orange) value and the other with an OK (green) value. The value propagated to the service using the "Best child" rule is that of OK (100):
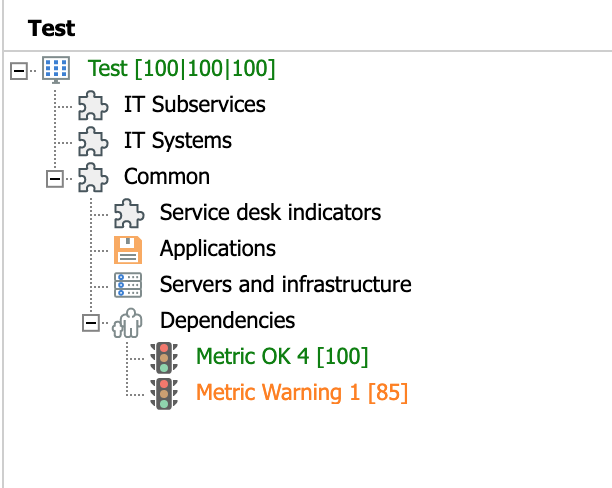
Worst child
This rule propagates the value of the child node with the lowest value. This is the default option for all nodes.
The following example shows two probes: one with a Warning (orange) value and the other with an OK (green) value. The value propagated to the service using the "Worst child" rule is that of Warning (85):

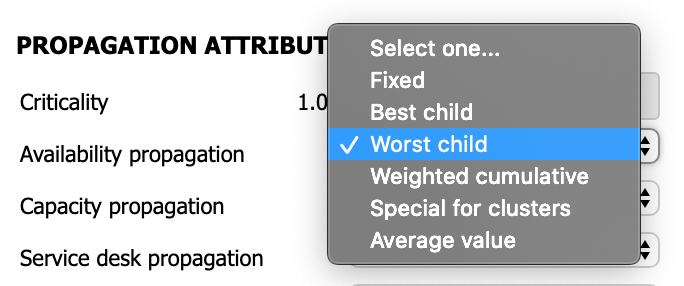
Weighted cumulative value
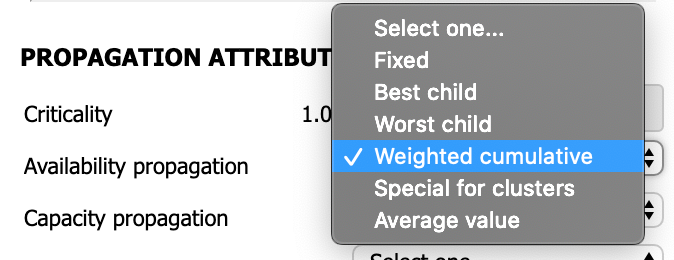
This rule propagates the weighted cumulative values of all probes. It is used for nodes composed of children with different criticality values. In contrast to the best and worst child rules, which focus only on the probe with the best and worst values respectively, this rule considers all the values of the probes to calculate the state of the service.
The following formula is used for calculating of the propagated value:

EXAMPLE:
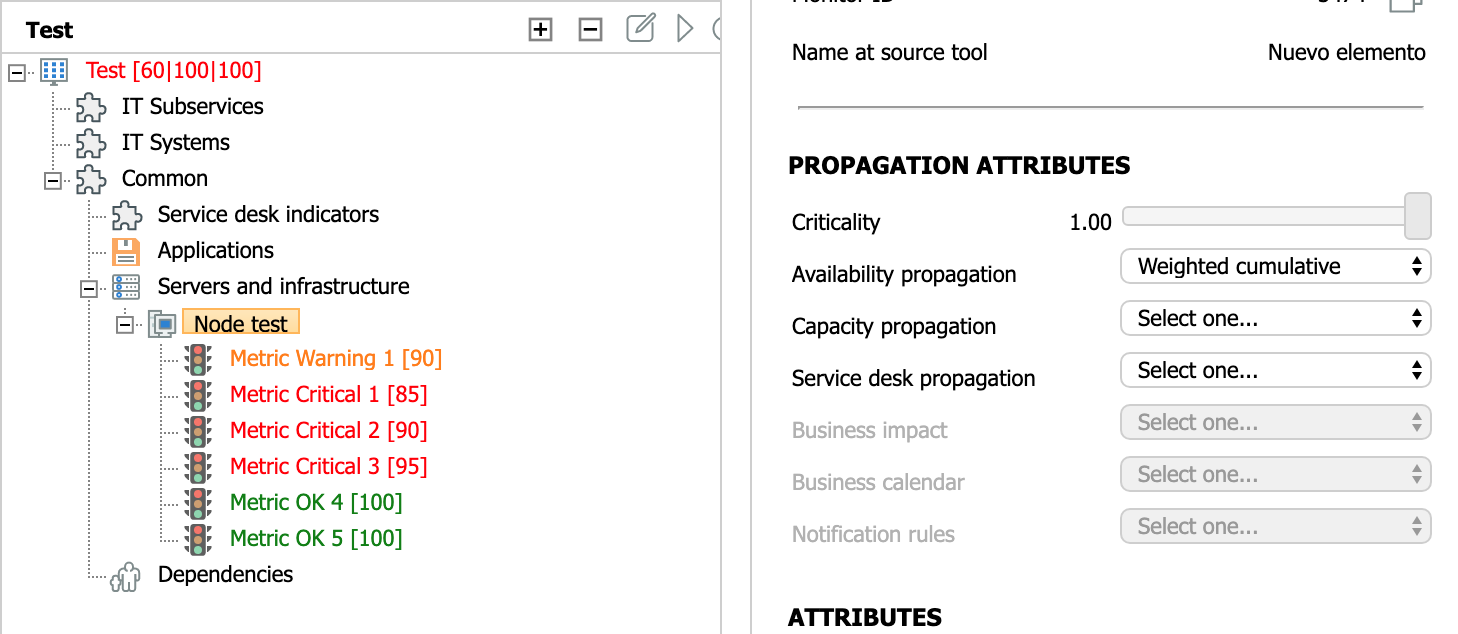
Below is a test node that receives values from six different probes and propagates an availability value according to the "Weighted cumulative value" rule. Each probe returns a different value, and all values are taken into account when calculating the state of the service:
Propagated value = 100 - [(100-90) + (100-85) + (100-90) + (100-95) + (100-100) + (100-100)] = 100 - (10 + 15 + 10 + 5 + 0 + 0) = 100 - 40 = 60
Special for clusters
Operation with Obsidian 2
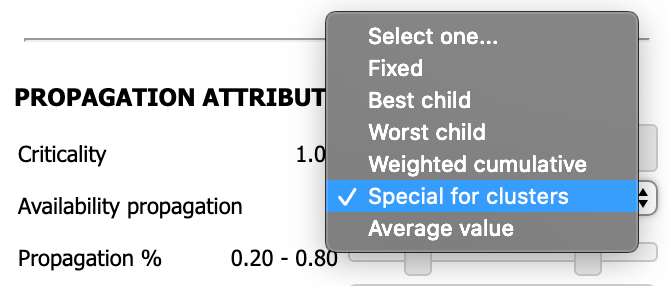
This rule allows you to weight the values of a set of child elements in percentages of Critical, Warning and OK. This is done as follows:
- When the special option for clusters is selected, a new field appears (% propagation):

- In order to complete this field, imagine the separation of sections as Critical → Warning → OK (in that order):
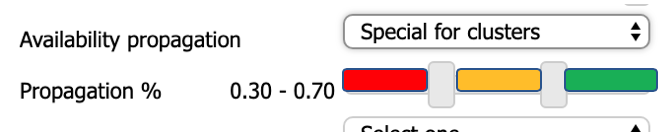
- The values of "% spread" will be assigned depending on the percentage of OK (green) child nodes required for each section. So, for this example:
- For 30% of OK child nodes or less, the return is a Critical value.
- If there are between 30% and 70% of OK child nodes, a Warning value is assigned.
- If there are more than 70% of OK child nodes, an OK value is obtained.
EXAMPLE:
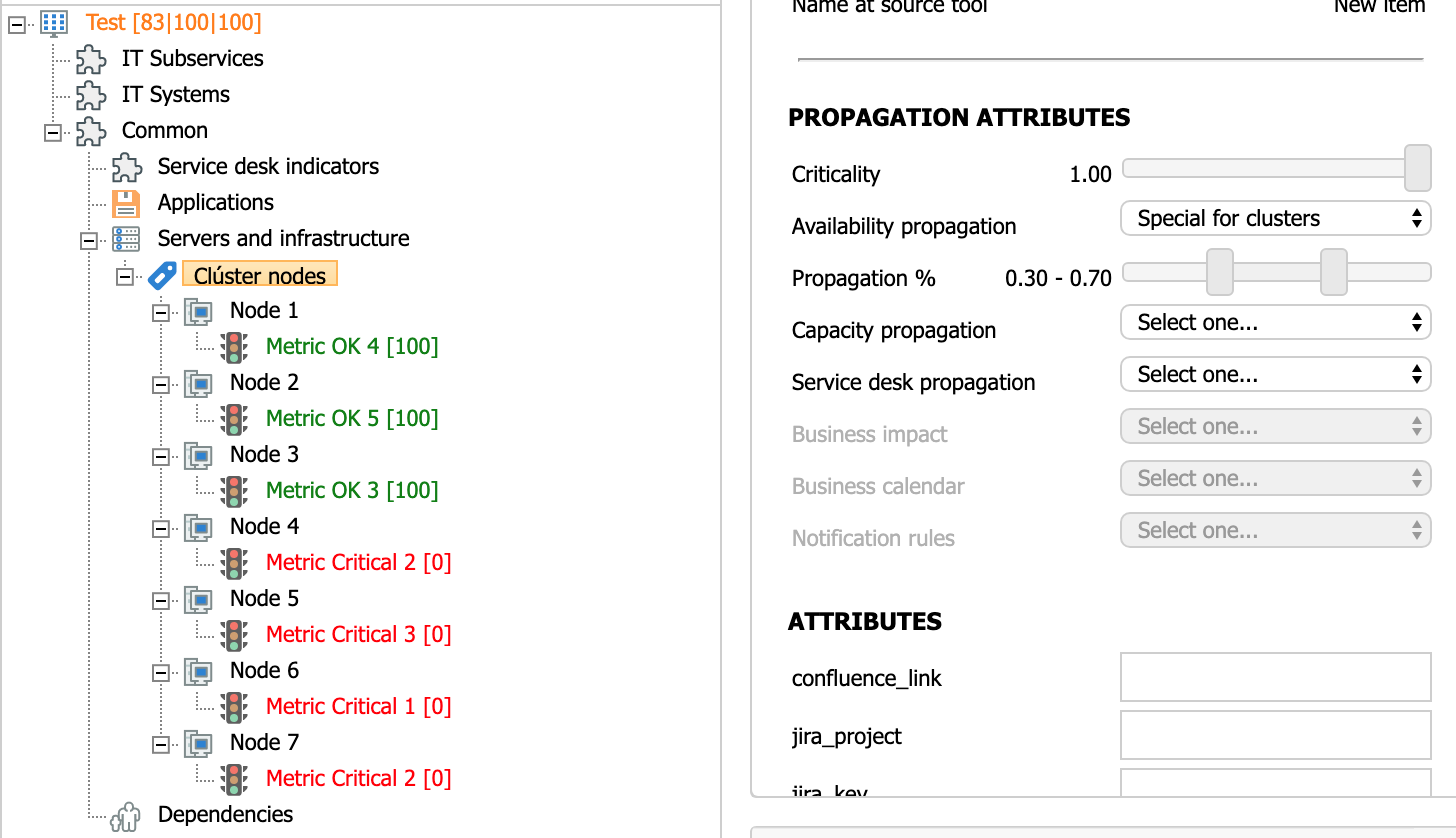
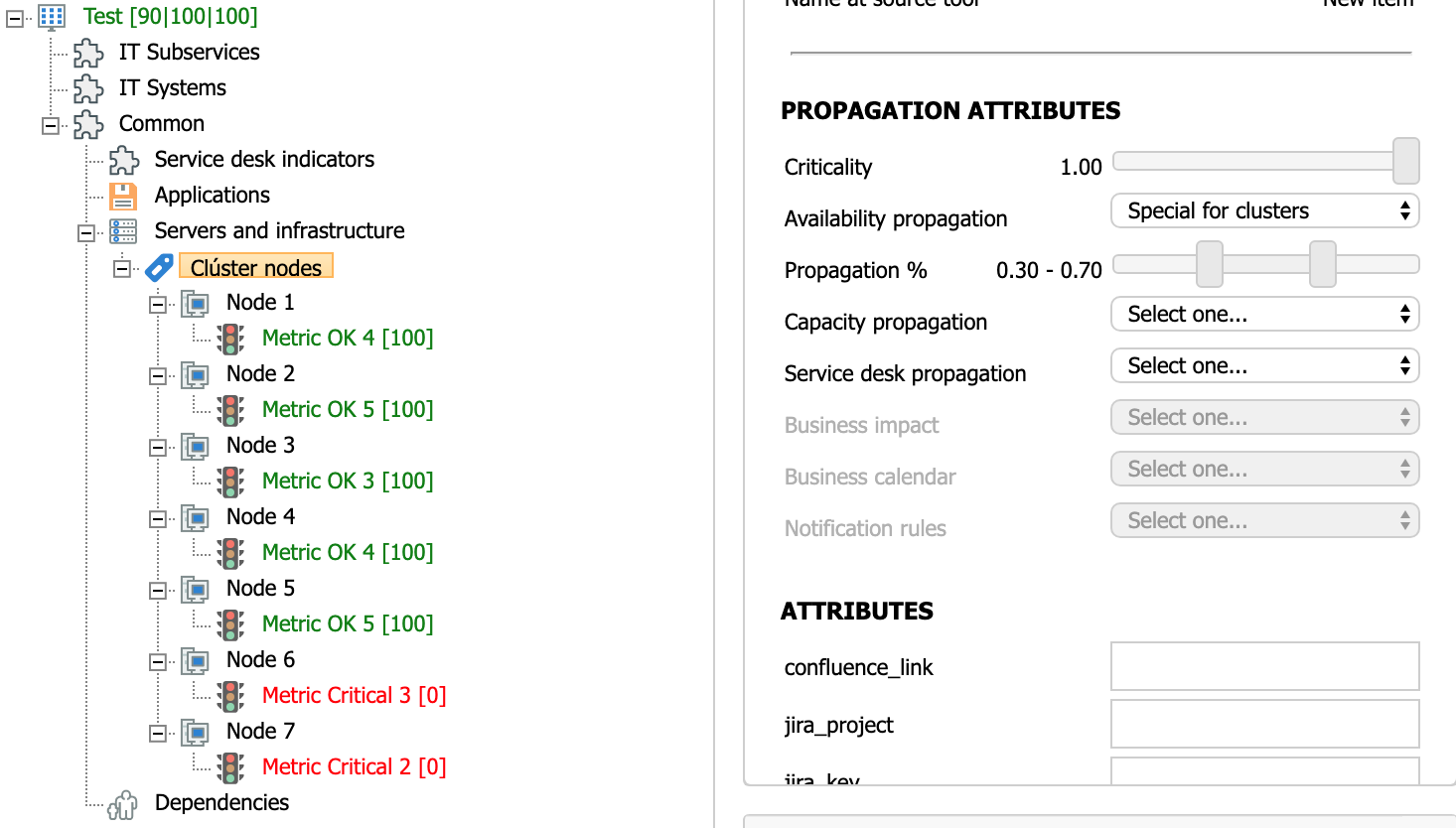
Below is a service that has a cluster of 7 nodes. Assuming the propagation percentages above (0.30 and 0.70) it follows that:
- 0.3 * 7 = 2.1 → 2. If there are only 2 OK nodes or less (5 or more KO nodes), a Critical value is assigned.
- 0.7 * 7 = 4.9 → 4. If there are between 2 and 4 OK nodes (between 3 and 5 KO nodes), a Warning value is obtained.
- If there are more than 4 OK nodes (2 or less KO nodes), the service will have an overall availability value of OK.
Operation with Obsidian 3 calculation engine
This propagation rule allows for the propagation of states based on the number of nodes with Critical and Warning values. This type of propagation is specially designed for clusters with more than 2 nodes.
When selecting the "Special for clusters" option, a new field will appear (% propagation):
Operation: The percentages of nodes that are in Critical and Warning states within the cluster are evaluated separately. Of the two evaluations, the one with the worst result will be propagated.
- Evaluation of Critical nodes:
- Imagine that in the field "% propagation", sections are separated as OK → Warning → Critical (in that order):

- The values of "% spread" will be assigned depending on the percentage of Critical (red) nodes:
- If the percentage of Critical nodes is between 0% and 29%→ an OK state will be propagated.
- If the percentage of Critical nodes is between 30% and 69% → a Warning state will be propagated.
- If the percentage of Critical nodes is between 70% and 100% → a Critical state will be propagated.
- Imagine that in the field "% propagation", sections are separated as OK → Warning → Critical (in that order):
- Evaluation of Warning nodes:
- Imagine that in the field "% propagation", sections are separated only as OK → Warning (in that order):

- Depending on the percentage of Warning nodes, the state that corresponds to that section will be assigned:
- If the percentage of Warning nodes is between 0% and 69%→ an OK state will be propagated.
- If the percentage of Warning nodes is between 70% and 100%→ → a Warning state will be propagated.
- Imagine that in the field "% propagation", sections are separated only as OK → Warning (in that order):
- Propagation of the worst state evaluated:
- The worst state of the two previous evaluations will be propagated:
- Worst state (Evaluation of Critical nodes, Evaluation of Warning nodes).
- The worst state of the two previous evaluations will be propagated:
EXAMPLE:
A service that has a 7 node cluster is shown below. Assuming the previous propagation percentages (0.30 and 0.70) we can calculate how many nodes we need to propagate in each segment:
- OK - Warning threshold: 0.3 * 7 = 2.1 → 2 nodes.
- Warning - Critical threshold: 0.7 * 7 = 4.9 → 4 nodes.
- Evaluation of Critical nodes:
- With 0 to 2 Critical nodes, an OK will be obtained.
- With 3 to 4 Critical nodes, a Warning will be obtained.
- With 5 to 7 Critical nodes, a Critical will be obtained.
- Evaluation of Warning nodes:
- With 0 to 4 Warning nodes, an OK will be obtained.
- With 5 to 7 Warning nodes, a Warning will be obtained.
- Propagation of the worst state evaluated:
- If there are, for example, 2 Critical nodes and 6 Warning nodes → Worst state (OK, Warning) = Warning.
- if there are, for example, 6 Critical nodes and 6 Warning nodes → Worst state (Critical, Warning) = Critical.
- If there are, for example, 3 Critical nodes and 4 Warning nodes → Worst state (Warning, Ok) = Warning.
Critical

Warning
OK
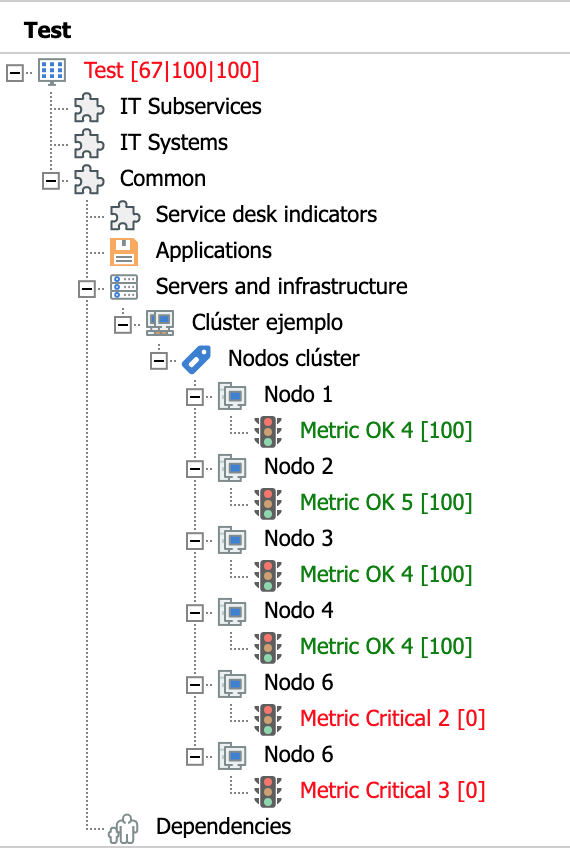
Average value
This rule allows the propagation of the average value of a set of child elements.
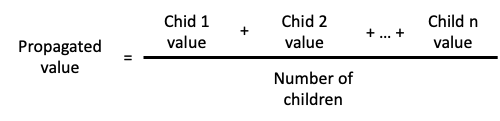
The following example shows a cluster with six nodes: two with a Critical value of 0 and four with an OK value of 100. The set-type node "Cluster nodes" has been assigned the propagation rule "Average value", so the value of the service is the average of all the values of its child nodes (in this case, 67):